

Finding Data Bugs in dbt Pull Requests
Data engineering is not software engineering, until it is

👋 Hi! I’m CL Kao, CEO of Recce and also previously version control system, open data and civic tech nerd. Find me on LinkedIn to connect!
This is an annotated presentation, using Simon Willison’s technique, from my talk at the dbt Taipei meeting earlier this year. It outlines Recce’s take in addressing the gap in software development practices for data-centric systems like dbt, and smarter systems built with AI.

Let’s Get Started
We made a new open source product called Recce, and I’d like to introduce it. Do you encounter data bugs, that is, problems caused by data, when using dbt? Does it cause difficulties? How do you handle it?
We’ve researched dbt, data quality and integrity for a while. In the past, we created a data quality check tool called PipeRider. However, after receiving market feedback, we realize solving the data problem requries addressing issues that are fundamentally different from traditional software engineering process.
Data Bugs
What are data bugs? Or rather, problems derived from data-centric systems. Here are some examples:
Zillow is a US real estate company. They previously had an initiative to automatically determine the value of houses. So if the value — the current market price — was lower than what the system thought it should be, they would automatically buy the house. This was a rather aggressive automated trading system, though there were some manual components. However, they found the algorithm was wrong and lost around 300 million USD. Strictly speaking, this is more a modeling and business strategy failure than just data.
Unity is the game engine company. They had a data pipeline error which led them to put out ads incorrectly, losing around 100 million dollars.
The costs derived from bad data are often hard to imagine, but some past research has pointed out that bad data probably costs a company up to 25% of revenue.

There’s also a recent interesting example with the LLM-based Air Canada chatbot. It agreed to a refund request from a customer, but Air Canada said they didn’t authorize the AI to agree to refunds. So they argued back and forth until eventually Air Canada had to pay out as their customer service rep said it was OK.
So how big can the problems with data-driven systems actually get?
Even if we don’t have fully automated systems, but instead use BI reports for decision making, some pretty scary things can still happen. We’ve interviewed people in the past who shared stories like their customer engagement reports showed exponential growth. Everyone thought things were going well so they invested more heavily. A month or two later they discovered “oh shit, that join was wrong.”
dbt, Data Pipeline as Code
dbt has already become a very important paradigm in the data stack, an extremely good tool. You can think of it as data pipeline as code. That is, we use code today to define data logic.
What are the benefits of the code approach? First, of course, is version control — everyone knows who changed what when. But the key point is you can test it. You can do code reviews and other software best practices like modularization, reusability with consistent definitions, and even higher order functions for more advanced use cases.
Many Types of Tests
When discussing data quality issues, people usually start with testing.
How do we verify the correctness of our data? Later I’ll quickly ask what people’s current approaches are, but with dbt there are built-in tests already — basic data tests for things like null values, duplicates, etc. You can use extensions like dbt-utils or dbt-expectations for more advanced things like range checks, reference checks, etc.
These kinds of tests mainly verify the state of the data itself. You have to access the data contents to validate if it’s correct or not. But here’s the catch — by the time you can test the data, the data is already there. So if the test fails, the data is already bad. The best outcome is you now know there’s bad data that needs to be fixed. Unless you set up more complex environments, you usually won’t discover issues until after bad data has already made it in. It might be ok if these are internal reports and you can fix them before your boss sees the errors. What if there are downstream tables that provide customer facing data?
So that’s the limitation if you only test the data state itself. The second approach is to look at the logic, not the data contents directly. Is the data transformation logic correct or not? This is usually called a unit test in software. You feed in some fake data, then check if the output matches what you expect based on your predefined logic for the given fake inputs. There are many unit testing frameworks. Which one do you use?
dbt core 1.8 introduced these unit tests, which are invoked with
dbt unit.https://hub.getdbt.com/EqualExperts/dbt_unit_testing/latest/
So things are progressing and changing quickly in this space. If you’ve tried using dbt’s various unit testing capabilities, you’ve probably found the overhead high. You have to write a lot of boilerplate YAML, the test data insertion is clunky, macros need lots of escaping to serialize the test data properly. Overall it feels like a lot of work just to write some tests.
Quick Polls
So what should we do? Having tests is still better than no tests. Let’s do a quick poll:
Do you run dbt tests? Wow, so many people don’t run tests.
Do you have CI? How long does each CI run take? Some people raise their hands. I guess it’s somewhere between 10 minutes and an hour.
OK, so CI here refers to various tests that run automatically when you create a pull request. You can do simple linting to check if the SQL code formatting looks sane, all the way to a full dbt run with test execution against a replica of production data in a dev environment.
Some even more advanced setups will run data comparisons between the old and new models, similar to our previous tool PipeRider, and other products like Datafold. I’ve heard of some really slow CIs where a single PR takes 1–2 days to complete because the full test run is so long. This is quite painful.
As mentioned, there’s a famous quote that you can only pick two between “fast, good, and cheap”. So if you want high quality, you have to invest significant time whether by human or machine. We’ll discuss this more later.
Let me also quickly ask another question? Is your dbt result customer visible? Is the output directly customer facing, or only viewed by your team internally? Is the result of your dbt models directly exposed to end users as part of the product?
We’re seeing an increasing trend where previously you’d use a separate analytics stack for things like analyzing usage patterns for each customer if you’re in a SaaS company, or ecommerce order analysis. But now there’s a trend to consolidate some of that logic into the data stack because so much of the analysis is repetitive and standard.
So the logic around things like defining good customers, high-value customers, etc. can be quickly adjusted by business users when it’s part of the data pipeline. Then that result can be exposed back to end users in the software products. We’ve seen several companies adopt this approach of consolidating the definitions between their software and data systems.
But this introduces a big problem: traditionally software has a lot more testing, aiming for high code coverage with unit tests, integration tests, behavioral tests, etc. By moving logic directly into the data stack and then exposing it back to software, there ends up being a gap — parts that haven’t been properly validated.
What could happen when this results in incorrect data or computations and it is sent back to users? We heard of one company operating an Uber-like marketplace where service providers can be rated by customers. Once they moved the rating logic directly into the data models and then back to software, an issue crept in and suddenly customers were complaining “why did my rating drop from 4.5 to 3.8?!”
So their support team was completely overwhelmed with everyone complaining about the rating decrease also impacting their revenue. The team had to scramble for a week working only on fixing this problem instead of any other tasks. You can see the correctness becomes really important when dbt outputs feed directly into customer-facing products.
What’s Not Working
So how is everyone currently solving these problems? There are two common approaches: copying software practices. First is observability — constantly checking for anomalies similarly to how application performance monitoring works, logging everything across all the systems. Like DataDog for Data.
But this has the same downsides we discussed early on with purely testing data state after the fact — by the time you detect an issue, damage has already occurred. While finding problems quickly is important to fix them, having your team constantly addressing emergencies places huge stress levels on everyone. Like the above Uber-like marketplace example, they would have engineers focused on nothing besides fixing data issues for an entire week.
The second approach is adding more CI checks, as some people already mentioned. But as we discussed earlier, data tests behave differently than software tests. Like Tests & CircleCI for Data. Software testing best practices dictate more tests are better for confidence. Data tests on the other hand often validate state after modifications have already occurred. So while more validation is helpful, you now need to manually inspect and interpret each and every result.
If I have 500 dbt model test impacts, it’s impossible to review 500 dashboards. We understand the “what so” of things changed, but so what? I can tell that something happened based on the outputs, but have no idea how to reason about the root cause or whether the models are still correct or not. This puts a significant burden onto the reviewers responsible for interpreting and approving changes.

Let’s look at a concrete example directly from a pull request with only a minor one-line SQL modification. It’s difficult to clearly articulate what needs validated even for a change this simple. Should I check which downstream models are impacted? What else do I need to verify before approving this? The current process offers little guidance.
Spot Checks are Still Required
So despite various forms of automated testing via dbt tests, CI, etc., we’ve found that manual spot checks are still essential during the dbt code review process, based on numerous user interviews. These are ad hoc queries and sanity checks on the data itself, similar to what people likely do even in production environments before and after deploying changes. While not formal tests, they provide a quick way to build confidence.
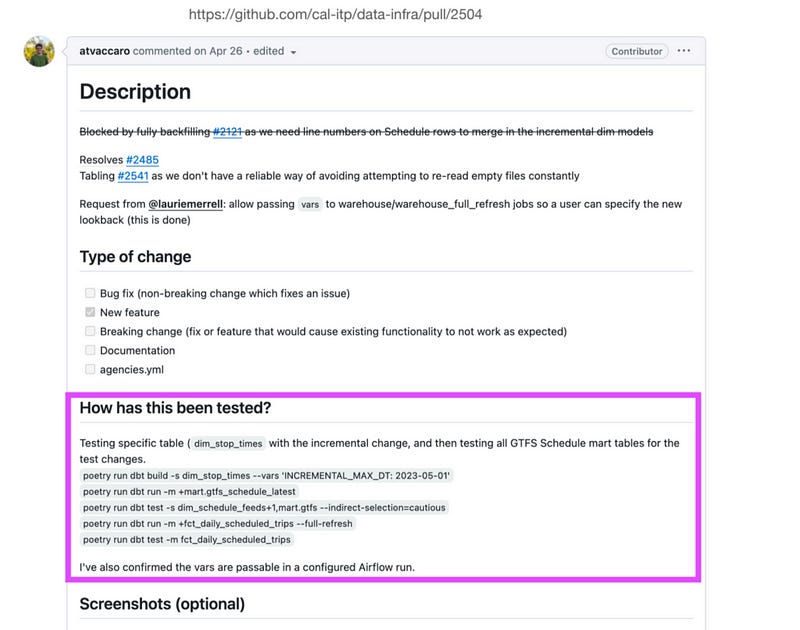
For example, this public dbt repository from a California government transportation agency shows reviewers discussing specific queries run and results checked as part of the pull request validation before approving the merge. The author notes what validations they already performed while the reviewer runs additional checks manually, as different people might be responsible for developing versus reviewing changes.

Take another PR for example, the author specifies “How has this been tested?” on the PR. What will he execute for testing in this PR, what are related and required to be tested for this PR? It provides a good practice that we don’t approve PR by simply checking dbt test results. We’ll review some specific spot checks related to this PR.
Before we go into the demo, it’s worth mentioning another repository from the open source Slack alternative Mattermost. They have 2 public repositories: old and new. We did some comparison. The old one has 1000+ models and the new one has 128 models. Maybe they refactored the whole codespace. The largest difference is “avg. merge time (seconds).” The old one seems probably do changes and just merge. The new one adds more test and checklist so take longer time to merge. This change increases 6X the avg. merge time. It echoes what we mentioned earlier: if you want high quality, you have to invest significant time whether by human or machine.

Recce: Data Reconnaissance
So we saw an interesting opportunity that is why Recce was born. We found a way to achieve the impossible “cheap, fast, good” in ensuring correctness in data-centric software.

How do we make it possible?
Let me talk about jaffle shop and come back here later. Do you know what a jaffle is? It’s called a sandwich press in the US. In dbt’s famous jaffle-shop-classic repository, the CLV(customer lifetime value) is wrong. CLV means how much the customer spends on your products in his/her lifetime. Well but in the code, it counts returned orders as lifetime value incorrectly! If you report CLV like this, you may be fired!
How can we fix this? Since we know the data impact is huge, we want to do more validation before making changes in production.

Fix the CLV error.
Let me mention a hot keyword: column-level lineage. Column-level lineage provides fine-grained information on dataset dependencies. dbt provides table-level lineage. When it announced that column-level lineage was launched and only available in dbt Cloud, it made people annoyed. The thing that upset people most was column-level lineage of dbt Cloud built on top of SQLMesh’s open-source technology SQLGlot. So the author of SQLMesh tweeted:
But there’s an open source alternative to dbt cloud…@SQLMesh , where column level lineage is free and open source for everyone to use.
Anyway, I think there’s no right or wrong. Corporates should do business. I mention column-level lineage here to explain and show where the orders.status column comes from.

Recce Demo
If you have a computer, please open the pull request page: https://github.com/DataRecce/jaffle_shop_duckdb/pull/1. It’s a typical PR that we use to demo the CLV example I just mentioned. How can we review the code change? We may not write a dbt test for it but we’d like to know who the impacted customers will be. Take one customer to check if the completed orders counts are the same as before. You’ll do some spot checks. The problem we observe is: if the PR author is cautious, s/he may provide the proof of checks in the PR. However, it’s hard to reproduce. So what does Recce do? We want to help you prepare the proof of correctness, and make them reusable and rerunnable by the reviewers easily and fast.
Recce is open source. You can install and run it in your local environment. When you have a dbt change, you can run Recce with it. The first thing you open Recce: You’ll see the modified changes. The Lineage Diff — an analysis of what parts of the models are new versus changed versus removed as part of this PR. Yellow highlights changed components, green is new additions, red would show removed/deleted parts. This helps give a quick summary understanding of what’s being modified and what parts downstream might need more scrutiny during review.
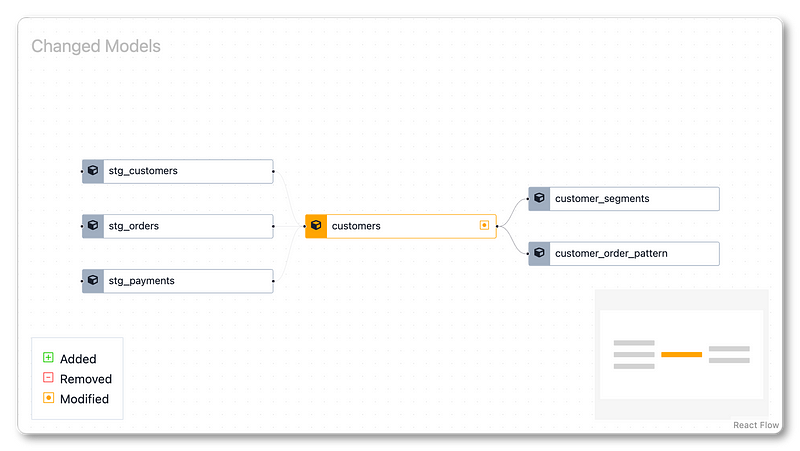
Over on the Checks panel, we can see metadata like the schema itself is unchanged in this PR, the specific line showing the code diff, etc. But here’s where it gets more interesting — we can select a model then choose an aspect we care to investigate around this change, like looking at column profile differences between the old and new model definitions.
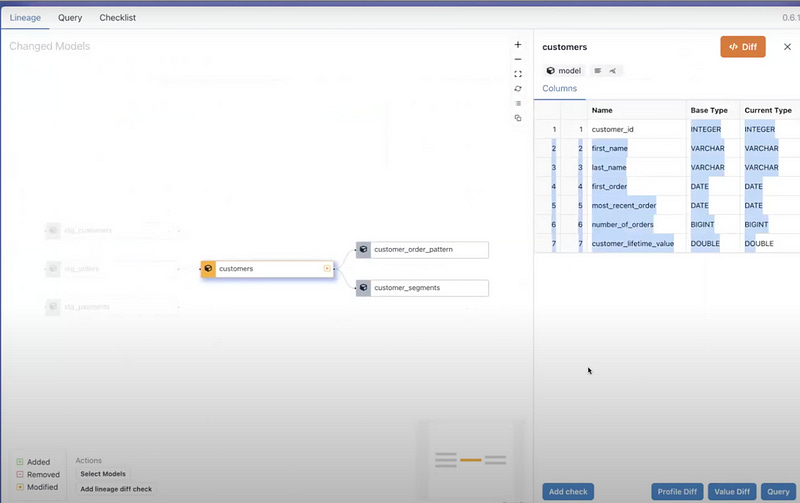
We immediately see the key results that customer lifetime value is impacted along with some distribution metrics, and row counts remain unchanged. If that seems reasonable, I can simply add this as a new check recording that specific observation to list out all the validations we want to document.
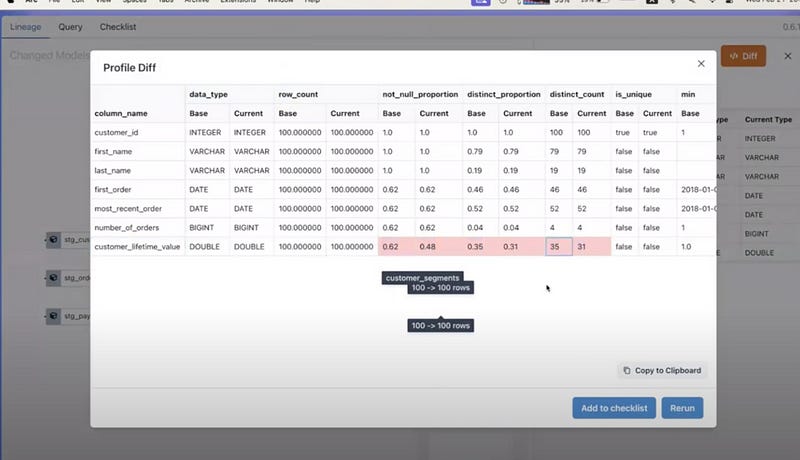
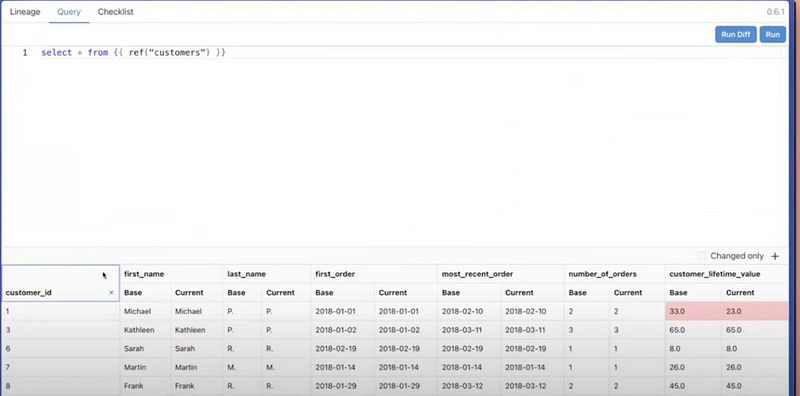
Going further, the ValueDiff view does a full comparison showing 73% of records are identical before and after — so 27% had their lifetime value updated probably due to previously counting refunded orders. I can again add this as a check while also examining the detailed underlying data — filtering for which customers had reductions. Then we might examine specific values for a few of those filtered individuals. You’ll see that it’s Michael who had 33 in customer_lifetime_value, now it turns into 23. Then you can select Michael to view if the sum of all completed orders are 23. You can add each thing you check into the checklist.
What is a check? Each check captures this point in time analysis before and after the change. They serve a similar purpose to tests by codifying expected behavior, but remain tied to the context of a specific code modification. In this example, it’s quite simple. We hope in the future these checks can be rerun (edit — this is now possible in Reccet). We might imagine checks created during initial development in a staging environment, then reapplied against production data after deployment to ensure no surprises or discrepancies. Authors can provide justification for changes while reviewers have an easier way to validate correctness.
Do you know Linear? They did a data change: delete cascade. It’s correct and passed in code review. No one was using that table. When you do delete cascade, it would delete all reference tables, too. Therefore, the production tables were deleted!! So 5 hours of data on production was lost with no backup. This is related to what we’re talking about but more seriously.
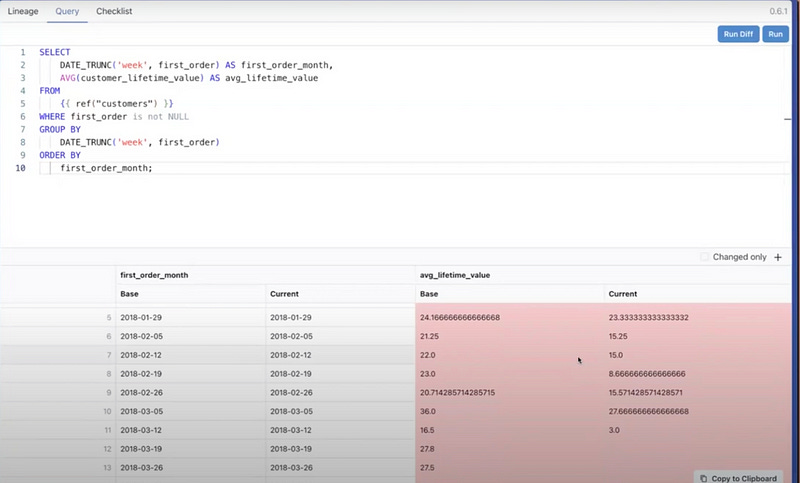
If your data is time series, you can create a custom query to track weekly changes of the customer_lifetime_value. You can add this to checklist so your PR reviewer can see your proof of correctness and your judgment. The author who makes the change should be able to prove his/her own works and provide reasons for correctness. We combine the “what so” and “so what” so the reviewers can easily understand the authors’ rationale by checking what the author checks and how they make the judgment without diving into every detail of the code and data. We offload the burden from the reviewers.
Back to Recce. We also provide other checks that you can easily add and some contextual convenience that you can easily dive into data. More are coming out.
Code Review for Data with Actionable Context
What does Recce do? It’s Data Reconnaissance. Code review for data with actionable context. We like to avoid product risks. We want to shorten the PR merge time by better collaboration. We believe in the future, there will be more data-centric products. These data products would have data security and compliance problems. Where did your data come from? Who approved this change? What evidence was provided? dbt is a tool to do data transformation. We like to help people do transformation. What definition of data changes? Where are the evidence supporting that? You can save all these into the Recce checklist. You can do it when you develop changes locally. Re-run it in your PR review process and production environment.

Why aren’t We Achieving the Copilot Experience in Data Systems
I recently wrote an article discussing why we haven’t achieved the same copilot developer experience when engineering data pipelines versus traditional software. Many data startup tools excel at SQL. With better context and great dbt doc, performance improves. However, when it comes to data modeling change, it’s hard to have the copilot experience. It’s okay to ask questions or for queries. But if I ask it to change the CLV definition to only include completed orders, it can’t do it. Not to mention the test and validation, as data tests differ from software tests.

When software developers do code changes, the mental effort is small. We can decide if we need a test now. The initial mental feedback loop is very tight. Since Copilot is actually autocomplete, it knows what I’m going to do next so it can autocomplete the to-do for me. It won’t do many tasks at a step. There are some conversational bots that you can ask for drafting larger chunk of code for you to modify later. But it’s not fast. If you do this, you need to constantly involve and review it. In short, with a comprehensive context and small tasks, AI can help you complete it fast. You can validate it quickly then decide to continue with AI or do it yourself. In software development, you do code change with fast mental check and later broader tests, and automate with CI tests. However, as mentioned in data, there’s often not enough context. Without good context, it’s lost in broader tests. That’s why it’s hard to ask AI to cut data engineering works into small pieces.
Recce checklist breaks down data engineering work. If we ask a LLM to fix a CLV issue, we validate and confirm the fix through an intermediate presentation — the checklist. With it, LLM can potentially plan and execute the changes to fix the issue, making the copilot experience possible.
Live Spot Checks
We turned the previous manual spot checks into a manageable, reproducible checklist. Authors can be proud of their work by doing the check and providing proof of correctness. Reviewers easily and quickly know what the authors have done. The checklist is collaborative and updatable.

Bonus: Awesome Public dbt Repo References
We’ve compiled a list of public dbt repository examples for learning how different organizations use dbt for analytics. Check out the awesome-public-dbt-projects for examples like data models from the Danish parliament, political contributions in Taiwan, and more. The largest repos are Mettermost, California ITP containing detailed transportation data, and GitLab, but their issues tracker isn’t public. I’d suggest checking out Mattermost and ITP repos in particular, to learn real-world production data modeling.
Please star Recce GitHub repo
Please star our Recce repository, ask any questions, and especially if you have in-progress dbt PRs, try running Recce against those to simplify reviews. We’d appreciate feedback on challenges performing quality assurance tests for dbt changes that Recce could help address.
Thank you!